décembre 2025
Détection d'anomalies dans des logs de sécurité (Isolation Forest)
Introduction
Les logs de sécurité sont des enregistrements générés par les systèmes informatiques afin de tracer les événements liés à l'activité des utilisateurs, des applications et du réseau. Ils permettent de conserver une trace détaillée des actions effectuées, telles que des tentatives de connexion, les accès aux ressources, ou les volumes de données échangées. En cybersécurité, l'analyse de ces logs jouent un rôle central dans la détection d'incidents, l'investigation post-attaque et la surveillance continue des systèmes. Cependant, le volume et la complexité de ces données rendent leur analyse manuelle difficile, voire impossible, ce qui justifie l'utilisation de méthodes automatiques comme le machine learning.
Dans ce travail, on simule des logs de sécurité réalistes et on applique un modèle de machine learning non supervisé afin d'identifier automatiquement des anomalies pouvant correspondre à des incidents de sécurité.
Données & hypothèses
Les données utilisées dans ce projet sont des logs de sécurité simulés conçus pour représenter des événements couramment observés dans un système d'information. Chaque ligne de données correspond à un événement de connexion et décrit à la fois le contexte temporel et l'intensité de l'activité associée. L'objectif de cette simulation est de reproduire un comportement majoritairement normal, tout en introduisant volontairement un faible pourcentage d'événements anormaux pouvant correspondre à des incidents de sécurité tels que des attaques par force brute ou des tentatives d'exfiltration de données.
Les logs contiennent les variables suivant :
- hour : heure de la journée à laquelle a lieu l'événement (0 - 23).
Cette variable permet de capturer des comportements dépendant du temps, par exemple une activité inhabituelle durant la nuit. - login_attempts : nombre de tentatives de connexion associées à un événement. Un nombre élevé de tentatives peut indiquer une attaque par force brute.
- bytes_sent : volume de données envoyées par le système. Des volumes anormalement élevés peuvent être liés à une exfiltration de données.
- bytes_received : volume de données reçues par le système. Cette variable complète l'analyse du trafic réseau et du comportement.
Ce projet repose sur les hypothèses suivantes :
- La majorité des événements observés correspondent à un comportement normal du système.
- Les événements malveillants sont rares et se distinguent par des valeurs extrêmes ou des combinaisons inhabituelles de variables.
- les anomalies peuvent être détectées sans connaissance préalable des attaques, à l'aide d'un modèle de machine learning non supervisé.
Sur la base de ces données et hypothèses, on applique un modèle de détection d'anomalies afin d'identifier automatiquement les événements suspects.
Méthodologie (Détection d'anomalie)
Afin d'identifier automatiquement des comportements suspects dans les logs de sécurité, une approche de détection d'anomalies non supervisée est adoptée. Ce choix est motivé par le fait que, dans un contexte réel de cybersécurité, les attaques sont rares et souvent inconnues à l'avance, ce qui rend difficile l'utilisation de méthodes supervisées. Le modèle retenu pour ce travail est Isolation Forest, un algorithme particulièrement adapté à la détection d'événements rares dans des ensembles de données de grande dimension.
Isolation Forest (intuition)
Isolation Forest repose sur l'idée que les anomalies sont plus faciles à isoler que les observations normales. L'algorithme construit un ensemble d'arbres aléatoires qui partitionnent l'espace des données. Les points anormaux, souvent éloignés du comportement majoritaire, nécessitent moins de partitions pour être isolés, ce qui permet de leur attribuer un score d'anomalie élevée.
Prétraitement des données
Avant l'entraînement du modèle, les variables sont standardisées afin de garantir une contribution équitable de chaque caractéristique. Cette étape est essentielle car les volumes de données et les nombres de tentatives de connexion sont exprimés sur des échelles différentes. La standardisation permet d'éviter qu'une seule variable ne domine le processus de détection d'anomalies.
Entraînement du modèle
Le modèle Isolation Forest est entraîné sur l'ensemble des logs simulés. Le paramètre de contamination est fixé de manière à refléter un faible pourcentage d'événements anormaux, conformément aux hypothèses de départ. Chaque événement se voit ensuite attribuer un score indiquant s'il est considéré comme normal ou suspect par le modèle.
A l'issue de l'entraînement, chaque événement est classé comme normal ou anomalie. Les anomalies détectées sont ensuite analysées à l'aide de visualisations afin de mieux comprendre les comportements identifiés comme suspects.
Graphique & interprétation
Le modèle Isolation Forest permet de distinguer deux groupes d'événements : un groupe majoritaire correspondant au comportement normal du système, et un groupe minoritaire identifié comme anomalie. Ces anomalies se caractérisent par des valeurs extrêmes ou des combinaisons inhabituelles de tentatives de connexion et de volume de données, pouvant correspondre à des incidents de sécurité potentiels. Le nombre d'anomalies détectées est cohérent avec l'hypothèse initiale d'un faible pourcentage d'événements anormaux.
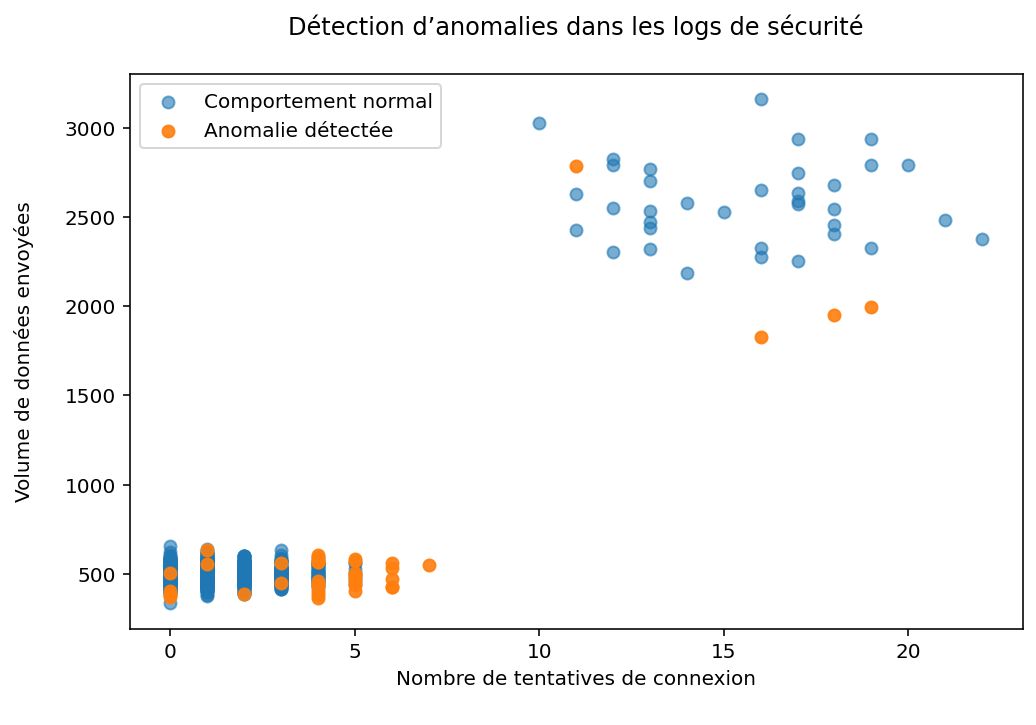
Figure 1 - Ce graphique représente la projection des événements de sécurité selon le nombre de tentatives de connexion et le volume de données envoyées.
Deux groupes distincts apparaissent clairement :
- un groupe majoritaire correspondant au comportement normal du système, caractérisé par des valeurs modérées ;
- un groupe minoritaire identifié comme anomalie, présentant des valeurs extrêmes ou des combinaisons inhabituelle de variables.
Ces événements anormaux peuvent correspondre à des événements de sécurité tels que des attaques par force brute ou des tentatives d'exfiltration de données.
Bien que certains événements présentent des valeurs élevées en nombre de tentatives de connexion et en volume de données envoyées, ils ne sont pas systématiquement classés comme anomalies.
Le modèle considère ces événements comme normaux lorsqu'ils s'inscrivent dans un comportement observé de manière répétée et cohérente selon les autres variables, telles que le moment de la journée ou le volume de données reçues. Les anomalies détectées correspondent ainsi à des combinaisons réellement atypiques et isolées dans l'espace multidimensionnel des données. En cybersécurité, un volume élevé d'activité n'est pas nécessairement synonyme de comportement malveillant ; c'est l'écart par rapport au comportement habituel dans un contexte donné qui détermine l'anomalie.
Extraits de codes
Génération des logs simulés
Les logs de sécurité sont simulés afin de représenter un comportement majoritairement normal, avec des caractéristiques réalistes issues de scénarios de cybersécurité courants :
data = pd.DataFrame({
"hour": np.random.randint(0, 24, n_logs),
"login_attempts": np.random.poisson(lam=1.5, size=n_logs),
"bytes_sent": np.random.normal(500, 50, n_logs),
"bytes_received": np.random.normal(1000, 100, n_logs)
})
Injection d'anomalies
Des anomalies sont volontairement injectées afin de simuler des incidents de sécurité, tels que des tentatives de connexion excessives ou des volumes de trafic anormalement élevés :
data.loc[anomaly_indices, "login_attempts"] += 15 data.loc[anomaly_indices, "bytes_sent"] *= 5 data.loc[anomaly_indices, "bytes_received"] *= 4
Prétraitement des données
Les variables sont standardisées pour garantir une contribution équilibrée de chaque caractéristique lors de l'entraînement du modèle de détection d'anomalies :
scaler = StandardScaler() X_scaled = scaler.fit_transform(features)
Détection avec Isolation Forest
Le modèle permet d'identifier les événements rares et isolés dans l'espace des données, sans nécessiter de labels préexistants :
model = IsolationForest(contamination=0.04, random_state=42)
data["anomaly"] = model.fit_predict(X_scaled)
data["anomaly"] = data["anomaly"].map({1: 0, -1: 1})
Conclusion
Ce travail illustre l'apport du machine learning non supervisé dans la détection d'anomalies appliquée à la cybersécurité. A travers la simulation de logs réalistes et l'utilisation d'un modèle Isolation Forest, il est possible d'identifier automatiquement des comportement atypiques sans règles prédéfinies. Bien que simplifié, ce travail met en évidence les enjeux réels de l'analyse de logs de sécurité et constitue une base solide pour des développements futurs sur des données réelles.