Mise à jour avril 2026
Évolution du modèle par enrichissement progressif des données
Introduction
Le phishing constitue l'une des principales menaces en cybersécurité, exploitant des messages frauduleux pour inciter les utilisateurs à divulguer des informations sensibles ou effectuer des actions malveillantes. L'objectif de ce projet est de concevoir un modèle de machine learning capable de distinguer des messages légitimes de tentatives de phishing à partir de leur contenu textuel.
Dans un contexte professionnel, ce type de problématique est au cœur des activités des équipes de sécurité et des centres opérationnels de sécurité (SOC). Les entreprises doivent quotidiennement faire face à des campagnes de phishing ciblant leurs collaborateurs, souvent via des emails ou des SMS frauduleux. L’enjeu est de détecter rapidement ces messages afin de limiter les risques de compromission des comptes ou de fuite d’informations sensibles.
Données utilisées
Le jeu de données utilisé dans ce projet est constitué de messages courts simulant des situations réelles, tels que des communications administratives légitimes et des messages frauduleux se faisant passer pour des institutions officielles. Les messages de phishing ont été construits autour de scénarios fréquemment observés, notamment des amendes à régler, des rappels urgents ou des menaces de sanctions.
Méthodologie
L'approche adoptée repose sur une méthode de classification supervisée. Les messages ont été transformées en représentations numériques à l'aide de la vectorisation TF-IDF, permettant de capturer l'importance relative des mots au sein de chaque message. Un modèle de régression logistique a ensuite été entraîné afin de prédire la probabilité qu'un message appartienne à la classe phishing
ou légitime
.
Évaluation et interprétation
Plutôt que de se limiter à une prédiction binaire, le modèle fournit pour chaque message une probabilité associée à chacune des classes. Cette approche permet une meilleure interprétation des résultats et met en évidence les cas ambigus, situés à la frontière entre messages légitimes et frauduleux.
Résultats - analyse qualitative
Les premiers résultats montrent que le modèle identifie correctement les messages contenant des formulations d'urgence ou faisant référence à des sanctions administratives comme des tentatives de phishing. A l'inverse, les messages informatifs standards, dépourvus de pression temporelle ou de menace explicite, sont majoritairement classés comme légitimes.
Les probabilités associées à chaque classe permettent d'interpréter la décision du modèle et de mettre en évidence les caractéristiques des tentatives de phishing, notamment les formulations d'urgence et les références à des sanctions. Par exemple, un message indiquant “Votre compte sera suspendu dans 24h, cliquez ici” serait typiquement identifié comme suspect en raison de la combinaison d’urgence et d’incitation à l’action.
| Type de message | Exemple de message | Probabilité légitime | Probabilité phishing | Décision |
|---|---|---|---|---|
| Légitime | Votre taxe foncière est disponible sur votre espace personnel | 0,53 | 0,47 | Légitime |
| Phishing | Vous avez une amen@e à payé sur ANTAI, cliquer ici pour régler | 0,35 | 0,65 | Phishing |
| Phishing | Votre compte est bloqué, pour le réactiver cliquez sur le lien | 0,34 | 0,66 | Phishing |
Afin d'évaluer plus globalement les performances du modèle, une analyse quantitative est réalisée à l'aide d'une matrice de confusion.
Interprétation en cybersécurité
Les résultats obtenus mettent en évidence des caractéristiques typiques des campagnes de phishing. Les messages frauduleux reposent souvent sur des mécanismes de pression psychologique, tels que l’urgence, la menace ou l’incitation à une action immédiate.
Ces éléments sont largement exploités par les attaquants pour contourner la vigilance des utilisateurs. Le modèle parvient ainsi à identifier des schémas récurrents utilisés dans les attaques réelles, ce qui en fait un outil pertinent pour assister les systèmes de filtrage automatisé.
Matrice de confusion
La matrice de confusion permet de visualiser la répartition des prédictions correctes et incorrectes, et d'identifier les principaux types d'erreurs commises par le modèle. Elle permet de comparer les classes réelles et les classes prédites par le modèle et de mettre en évidence :
- les messages correctement classés ;
- les faux positifs (légitime $ \rightarrow $ phishing) ;
- les faux négatifs (phishing $ \rightarrow $ légitime).
Afin d'évaluer l'impact de la qualité et de la diversité des données sur les performances du modèle, plusieurs itérations ont été réalisées. Chaque étape correspond à un enrichissement progressif du jeu de données avec de nouveaux exemples de messages légitimes et frauduleux. Les matrices de confusion ci-dessous illustrent l'évolution des performances du classifieur.
Test 1 - Classification sur un jeu de données initial
La matrice de confusion obtenue (figure 1), montre que le modèle détecte tous les messages de phishing, mais classe incorrectement une partie des messages légitimes comme phishing. Ce comportement illustre le compromis entre sensibilité et spécificité, typique des modèles de classification basés sur le texte. Dans un contexte opérationnel, un faux positif est moins critique qu'un faux négatif, car il peut être traité manuellement, tandis qu'un phishing non détecté représente un risque direct pour l'utilisateur.
L'enrichissement du jeu de données initial permet néanmoins d'améliorer la robustesse du modèle. C'est ce que l'on va observer dans les tests 2 et 3 suivants.
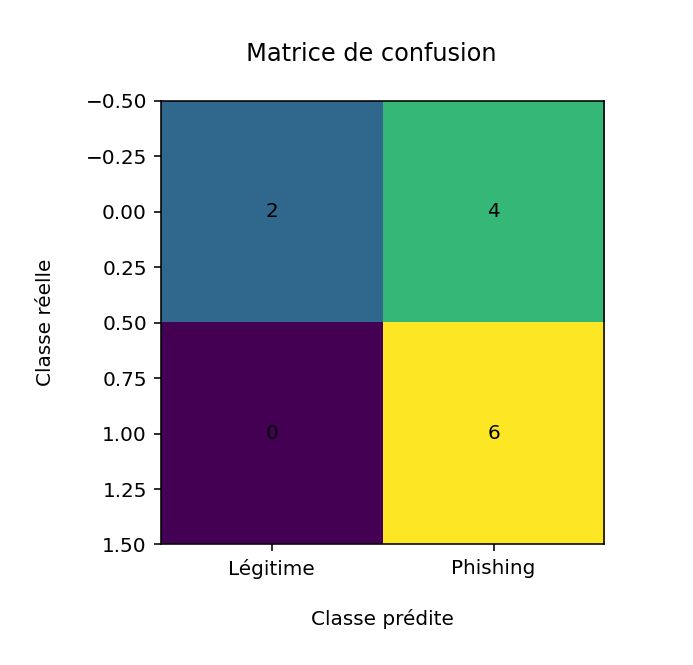
Figure 1 - Matrice de confusion obtenue avec la première évaluation sur un jeu de données limité.
Test 2 - Amélioration du modèle par ajout de nouveaux exemples
Après un premier enrichissement des données avec de nouveaux exemples de messages plus réalistes, le modèle obtenu montre une amélioration globale de l'équilibre entre détection des attaques et limitation de faux positifs. La nouvelle matrice de confusion met en évidence une bonne capacité de détection des messages frauduleux, tout en conservant des performances raisonnables sur les messages légitimes.
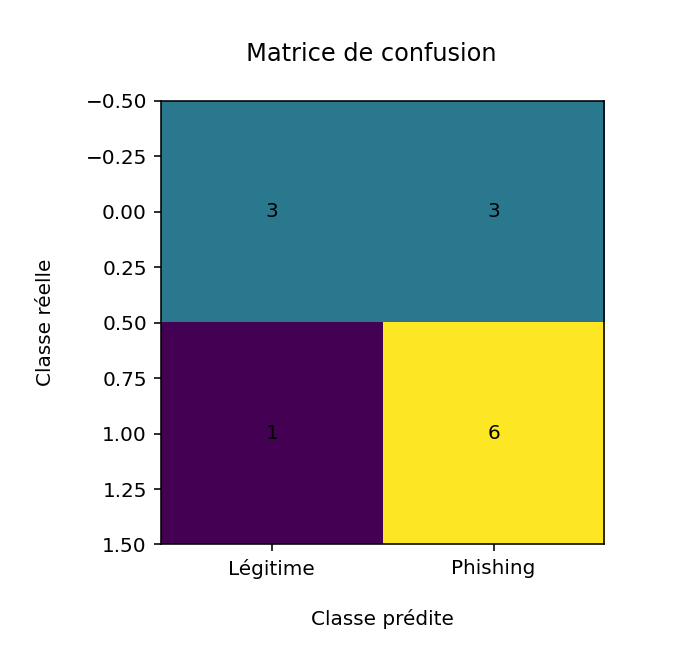
Figure 2 - Matrice de confusion obtenue après enrichissement du jeu de données initial.
Cette nouvelle matrice de confusion montre que le modèle identifie correctement 6 messages de phishing, tandis qu'un message frauduleux n'est pas détecté. Du côté des messages légitimes, 3 sont correctement classés, mais 3 sont incorrectement identifiés comme phishing.
En résumé, le modèle parvient à détecter la majorité des messages de phishing, avec un message frauduleux non identifié. En revanche, certains messages légitimes sont parfois considérés à tort comme suspects. Ce comportement est courant en cybersécurité et traduit un choix volontaire visant à privilégier la détection des attaques.
En cybersécurité, il est souvent préférable de tolérer quelques faux positifs plutôt que de laisser passer des attaques non détectées.
Test 3 - Stabilisation des performances après un second enrichissement
L'enrichissement progressif du jeu de données initial améliore significativement les performances du classifieur. La matrice de confusion finale montre un bon équilibre entre détection des messages frauduleux et limitation des faux positifs, avec une précision et un rappel proche de 88 % :
- les faux positifs (légitimes bloqués) : 1
- les faux négatifs (phishing non détectés) : 1
Ce compromis est particulièrement adapté à un contexte de cybersécurité.
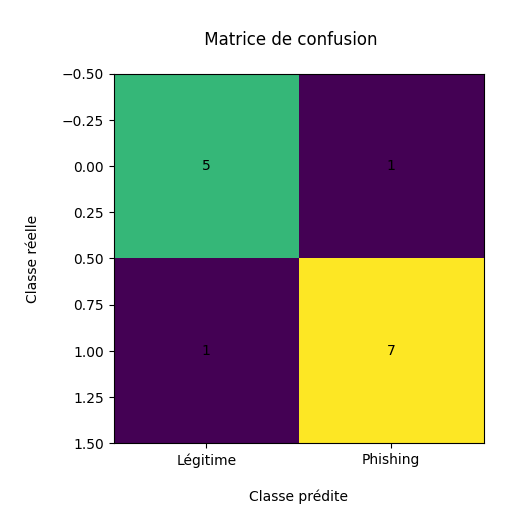
Figure 3 - Matrice de confusion obtenue après enrichissement avancé et stabilisation.
Intégration dans un environnement réel
Dans un environnement professionnel, ce type de modèle pourrait être intégré dans des solutions de filtrage des emails ou des passerelles de sécurité (secure email gateway). Chaque message entrant pourrait être analysé automatiquement afin d’attribuer un score de risque. Les messages présentant un score élevé pourraient être bloqués ou placés en quarantaine, tandis que les cas ambigus pourraient être transmis à un analyste pour validation. Cette approche permet de réduire significativement l’exposition des utilisateurs aux attaques de phishing.
Limites de l’approche
Malgré ses performances, ce modèle présente plusieurs limites. Les données étant simulées, elles ne couvrent pas toute la diversité des attaques de phishing observées en conditions réelles, notamment les attaques sophistiquées (spear phishing). De plus, le modèle repose uniquement sur le contenu textuel et ne prend pas en compte d’autres indicateurs importants comme l’URL, le domaine expéditeur ou les métadonnées du message. Enfin, les attaquants adaptent constamment leurs techniques, ce qui nécessite une mise à jour régulière des données et du modèle.
Perspectives d’amélioration
Des améliorations pourraient inclure l’intégration de nouvelles caractéristiques, comme l’analyse des liens présents dans les messages, la détection de fautes typiques ou l’utilisation de modèles plus avancés de traitement du langage naturel (NLP). L’utilisation de données réelles issues d’incidents de sécurité permettrait également d’améliorer la robustesse du modèle et sa capacité à détecter des attaques plus sophistiquées.
Conclusion
Cette démarche itérative met en évidence l'importance de la qualité et de la diversité des données dans les systèmes de détection. L'amélioration progressive des résultats illustre concrètement comment l'enrichissement du corpus permet d'augmenter la robustesse d'un modèle de classification appliqué à la cybersécurité.